icon: LiWrenchTitle: Prompt Chaining - Chaining Together Multiple Prompts
- LLMs Do Not Have Memory
- Prompting Techniques for Better Reasoning
- Multi-action within a Prompt
- Prompt Chaining
- Exception Handling
- Hands-on Walkthrough and Tasks

Why Bother with Prompts Chaining
-
✦ Essentially, prompt chaining involves taking the result of one prompt and using it as the starting point for the next, forming a sequence of interactions
-
By breaking a complex task into multiple smaller prompts and passing the output of one prompt as the input to the next, prompt chaining simplifies complex tasks and streamlines the interaction with the LLM model.
-
Instead of overwhelming the LLM instance with a single detailed prompt, we can guide it through multiple steps, making the process more efficient and effective.
-
It allows us to write less complicated instructions, isolate parts of a problem that the LLM might have difficulty with, and check the LLM’s output in stages, rather than waiting until the end.
-
Advantages of Prompt Chaining
The advantages of prompt chaining include:
-
✦ Simplified Instructions by Providing Specific Context
- By focusing on a specific context, instructions become clearer, making it easier for the model to understand and respond accurately.
-
✦ Focused Troubleshooting
- Helps in isolating specific issues by breaking down the problem into smaller, manageable parts.
- Allows for more precise troubleshooting and solution, as the troubleshooting process is focused on a particular aspect of the problem.
-
✦ Incremental Validation
- Validates the accuracy and relevance of each step before moving on to the next, ensuring the intermediate outputs are on the right track.
- Makes it easier to identify and correct errors at early stages, preventing compounding mistakes.
-
✦ Reduce the Number of Tokens in a Prompt
- Using fewer tokens can save computational resources and costs, especially important for large-scale applications.
- Shorter prompts can be processed faster, leading to quicker responses.
-
✦ Allow to Skip Some Chains of the Workflow
- Provides the ability to bypass certain steps that may not be necessary for every scenario, enhancing efficiency.
-
✦ Have a Human-in-the-Loop as Part of the Workflow
- Human oversight ensures that the AI's output meets the desired standards and can intervene when necessary.
- Humans can provide feedback and make adjustments in real-time, allowing the system to cope with unexpected situations or new information.
-
✦ Use External Tools (Web Search, Databases)
- Incorporating external tools can significantly extend the AI's abilities, allowing it to pull in current data, facts, or figures that it wouldn't otherwise have access to.
- Access to up-to-date information from the web or specific databases ensures that the AI's responses are both accurate and relevant to the user's query.
Major Chain Types
Simple Linear Chain
- ✦ We have actually applied the prompts chaining in an earlier example Technique 4 Least-to-Most Prompting
- It was a straightforward example because the output from
prompt_1can be taken wholesale intoprompt_2. - However, this is often not the case when our prompt get more complex (e.g., using
Inner Monologuetechnique) - Below is the core idea of how a simple linear chain can be implemented:
- It was a straightforward example because the output from
prompt_1 = " Generate 10 facts about the role of e-learning in the education sector"
response_1 = get_completion(prompt_1)
prompt_2 = f"<fact>{response_1}</fact> Use the above facts to write a one paragraph report about the benefits and challenges of e-learning in the education sector:"
response_2 = get_completion(prompt_2)
- ✦ Here is the example with the output.
Linear Chain with Processed Output from Previous Step
text = f"""
In a bustling HDB estate, colleagues Tan and Lee set out on \
a mission to gather feedback from the residents. As they went door-to-door, \
engaging joyfully, a challenge arose—Tan tripped on a stone and tumbled \
down the stairs, with Lee rushing to help. \
Though slightly shaken, the pair returned to their office to \
comforting colleagues. Despite the mishap, \
their dedicated spirits remained undimmed, and they \
continued their public service with commitment.
"""
# This code is modified from the earlier example in `inner monologue`
def step_1(text):
step_delimiter = '#####'
# example 1
prompt_1 = f"""
Your task is to perform the following steps:
Step 1 - Summarize the following text delimited by <text> with 1 sentence.
Step 2 - Translate the summary into Malay.
Step 3 - List each name in the Malay summary.
Step 4 - Output a json object that contains the following keys: malay_summary, num_names.
The response MUST be in the following format:
Step 1:{step_delimiter} <step 1 output>
Step 2:{step_delimiter} <step 2 output>
Step 3:{step_delimiter} <step 3 output>
Step 4:{step_delimiter} <step 4 output>
<text>
{text}
</text>
"""
response = get_completion(prompt_1)
# Process the output for next step
json_string = response.split('#####')[-1].strip()
dict_output = json.loads(json_string)
return dict_output
def step_2(dict_input_2):
prompt_2 = f"""
Write a short English news article within 200 words based on the Summary.
<Summary>
{dict_input_2['malay_summary']}
</Summary>
"""
response = get_completion(prompt_2)
return response
def run_linear_pipeline(text):
# Step 1
output_1 = step_1(text)
# Step 2
output_2 = step_2(output_1)
# Step N..
# output_n = <...>
# Return final output
final_output = output_2
return final_output
run_linear_pipeline(text)
The example above demonstrates a two-step linear pipeline where the goal is to first summarize and translate a given text into Malay, and then the second step uses the translated summary to generate a short English news article. Here's a breakdown of the key components and how they work together:
Chain 1:
- ✦ Function
step_1:- This function takes a piece of text as input and constructs a prompt that instructs the LLM to perform a series of tasks:
- Summarize the text in one sentence.
- Translate the summary into Malay.
- List each name found in the Malay summary.
- Output a JSON object containing the Malay summary and the number of names listed.
- This function takes a piece of text as input and constructs a prompt that instructs the LLM to perform a series of tasks:
- ✦ The prompt is sent to the LLM via the
get_completionfunction (a placeholder for the actual LLM API call), and the response is processed to extract the JSON string, which is then parsed into a dictionary (dict_output) and returned.
Chain 2:
- ✦ Function
step_2:- This function receives the dictionary output from
step_1as input. - It constructs a new prompt asking the LLM to write a short English news article based on the Malay summary provided in the dictionary.
- The function then sends this prompt to the LLM and returns the generated news article as the response.
- This function receives the dictionary output from
Running the Pipeline
- ✦ Function
run_linear_pipeline:- This function orchestrates the execution of the pipeline.
- It first calls
step_1with the original text, capturing its output (the dictionary containing the Malay summary and the number of names). - This output is then passed to
step_2, which generates the English news article. The final output (the news article) is returned by the function.
Diagram below shows the relationship of the 3 functions in graphic

Decision Chain
-
✦ Decision chain demonstrates a powerful
chaining patternfor building dynamic and adaptable conversational AI systems: Decision Chaining.- This approach leverages the inherent flexibility of Large Language Models (LLMs) to create a chain of prompts, where each step's response informs the subsequent decision point in the conversation flow.
-
✦ Imagine a traditional program trying to understand a user asking for a "fee waiver," potentially for a late payment. Rigid keyword-based systems might fail if the user doesn't use the exact term "late fee waiver." This is where LLMs, acting as "soft programming logic," shine.
- In our example below, the first prompt asks the LLM to analyze the user's message and make a simple decision: Is this about a "Late Fee Waiver" (Yes/No)? This isn't about keyword spotting; the LLM understands the intent behind the user's words.
- Based on this initial "soft" decision, the conversation branches. If the LLM detects a request for a waiver, the next prompt is tailored to gather the necessary information for processing. If it's a general question, the LLM receives a different prompt, guiding it to provide a helpful answer.
-
✦ Diagram below is a graphical representation of the chain.
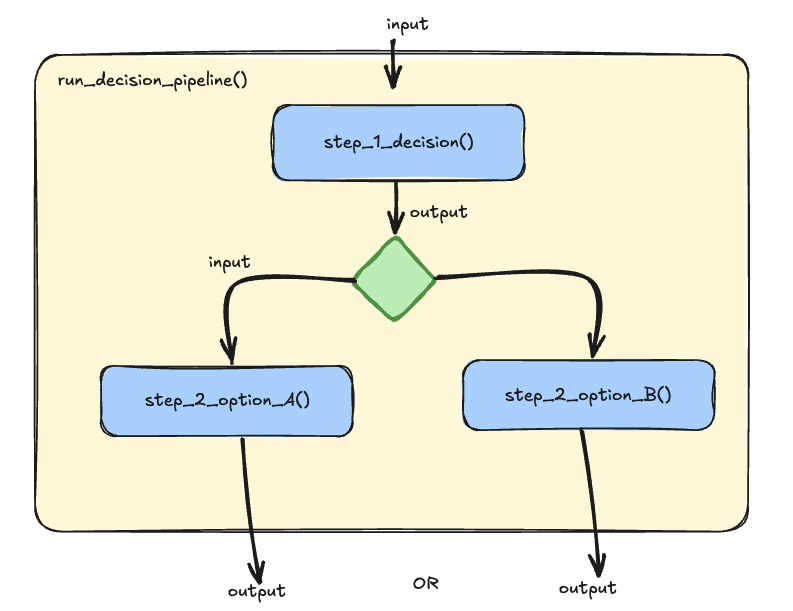
- ✦ Decision chain pattern, guided by LLM-powered decisions, offers several advantages:
- Robustness to Vague Input:
- Users can express themselves naturally, without needing to use hyper-specific language.
- Dynamic Conversation Flow:
- The conversation adapts in real-time to the user's needs, leading to a more natural and engaging experience.
- Simplified Development:
- Instead of writing complex rules for every possible user input, we focus on crafting clear prompts that empower the LLM to make the right decisions.
- Robustness to Vague Input:
Prompts Chaining and Performance
-
✦ While prompt chaining enhances the quality of the conversation, it can also impact the performance or speed of the AI system.
- One reason is that as the conversation progresses, the chain of prompts becomes longer.
- Processing these longer inputs can take more time and computational resources, potentially slowing down the response time of your application.
-
✦ Despite this, the benefits of prompt chaining often outweigh the potential performance costs.
- The ability to maintain a coherent, context-aware conversation is crucial for user engagement and satisfaction.
- Therefore, it's important for developers to measure the time performance of the chain, in order to balance conversational quality with system performance.
- ✦ The
%%timeitmagic command in Jupyter Notebook (strickly speaking the underlying IPython) is used to measure the execution time of code.- It’s a built-in magic command in IPython, with the double percentage sign %% indicating that it is a “cell magic” command.
- Cell magic commands apply to the entire code cell in an IPython environment, such as a Jupyter notebook.
- ✦ When we run a cell with
%%timeit, IPython will execute the code multiple times and provide a statistical summary of the execution times.- This includes the best, worst, and mean execution times, along with the standard deviation, giving you a comprehensive overview of your code’s performance.
- ✦ It’s important to note that
%%timeitautomatically determines the number of runs and loops for you based on the complexity of your code.- However, you can also manually specify the number of runs (using -r) and loops (using -n) if you want more control over the timing process.
- For example,
%%timeit -r 5 -n 1000would run the code 1000 times per loop for 5
- ✦ There is a similar command you can try in Jupyter Notebook to test the response time of your pipelline (or any code execution within a cell) is
%%time: This magic command is used to time a particular piece of code.- Unlike
%%timeit, it does not run the code multiple times, so it provides the time taken for a single run. - This can be useful for longer running pieces of code where running it multiple times (like
%%timeitdoes) would be impractical
- Unlike
[Extra: ] How about LangChain?
LangChain is a framework to build with LLMs by chaining interoperable components. The framework "abstracts" away many of the complexity, so developers will have to write shorter code to achieve similar outputs. It is useful for projects that involves complex prompt chains where we need to orchestrate multiple LLM calls with different prompts and data dependencies.
Prompt Chaining vs. LangChain
| Aspect | Native Prompt Chaining | LangChain |
|---|---|---|
| What is it | Involves taking the result of one prompt and using it as the starting point for the next, forming a sequence of interactions. | A framework designed to simplify the creation of applications that use language models, providing tools for chaining prompts, managing state, and integrating external data sources. |
| Advantages | - Simplified Instructions: By focusing on specific contexts, instructions become clearer. - Focused Troubleshooting: Helps isolate specific issues by breaking down the problem into smaller parts. - Incremental Validation: Validates each step before moving on, ensuring intermediate outputs are correct. - Reduced Token Usage: Using fewer tokens can save computational resources and costs. |
- Ease of Use: Provides a higher-level abstraction, making it easier to create complex chains. - State Management: Built-in tools for managing state across multiple prompts. - Integration: Seamlessly integrates with various data sources and APIs. - Modularity: Highly modular, allowing for reusable components. - Community and Support: Active community. |
| Disadvantages | - Complexity: Requires manual handling of each step and its output. - Performance: Longer chains can impact performance and response time. - Error Handling: Requires explicit handling of exceptions and errors. |
- Learning Curve: May require learning the framework and its conventions. - Overhead: Additional abstraction layers can introduce overhead. - Dependency: Relies on the LangChain framework, which may not be suitable for all use cases. - Active Development: Updates are often not backward compatible and may break the app/code. Documentation may not reflect the latest changes and not comprehensive. |
| Flexibility | - High Flexibility: Can be tailored to specific needs and scenarios. - Customizable: Each step can be customized extensively. |
- Moderate Flexibility: Provides flexibility but within the constraints of the framework. - Predefined Patterns: Encourages the use of predefined patterns and best practices. |
| Scalability | - Manual Scalability: Requires manual effort to scale and manage larger chains. | - Built-in Scalability: Designed to handle larger chains and more complex workflows efficiently. |
| Error Handling | - Manual Error Handling: Requires explicit handling of errors at each step. | - Automated Error Handling: Provides built-in mechanisms for error handling and retries. |
| Human Oversight | - Human-in-the-Loop: Allows for human intervention and oversight at various stages. | - Limited Human Oversight: Primarily automated, but can be configured for human intervention. |
| Use Cases | - Custom Workflows: Suitable for highly customized workflows and specific tasks. - Research and Development: Ideal for experimental setups and iterative development. |
- Production Applications: Suitable for production-grade applications with complex workflows. - Rapid Prototyping: Ideal for quickly prototyping and deploying language model applications. |
Our Two Cents
-
✦ While LangChain offers a powerful framework for working with language models, we believe that a foundational understanding of prompt chaining is essential for anyone venturing into this field.
-
✦ This training prioritized a direct "Native Prompt Chaining" approach to provide you with that fundamental knowledge and transparency into the underlying mechanisms. It empowers you to build and troubleshoot chains with greater control and flexibility.
-
✦ This is not to say LangChain should be disregarded entirely. As your projects grow in complexity and you require advanced features like state management and external integrations, exploring LangChain's capabilities can be incredibly beneficial.
-
✦ Ultimately, having a strong grasp of the core concepts of prompt chaining will equip you to make informed decisions about the best tools and frameworks for your LLM-powered solutions or applications.